我们正式发布 GPT-5.5——我们迄今为止最智能、最直观易用的模型,也是迈向全新计算机工作方式的下一步。
GPT-5.5 能更快理解你的意图,并承担更多工作。它擅长编写和调试代码、在线研究、分析数据、创建文档和电子表格、操作软件,并在不同工具间切换直至任务完成。你无需精心管理每一步,只需交给 GPT-5.5 一个杂乱的多步骤任务,它就能自主规划、使用工具、检查工作、处理模糊情况并持续推进。
这些提升在智能体编程(agentic coding)、计算机使用、知识工作和早期科学研究领域尤为突出——这些领域的进展依赖于跨上下文推理和长期行动。GPT-5.5 在实现智能跃升的同时并未牺牲速度:通常更大、更强的模型服务速度更慢,但 GPT-5.5 在实际服务中的每 token 延迟与 GPT-5.4 相当,智能水平却大幅提升。它在完成相同的 Codex 任务时使用的 token 数量也显著减少,因此更高效、更强大。
我们发布了迄今为止最强的一套安全保障措施,旨在减少滥用风险,同时保留有益工作的访问权限。我们在完整的安全和准备框架下对该模型进行了评估,与内部和外部红队合作,针对高级网络安全和生物学能力进行了专项测试,并在发布前收集了来自近 200 位受信任的早期合作伙伴的真实使用反馈。
即日起,GPT-5.5 向 ChatGPT 和 Codex 中的 Plus、Pro、Business 和 Enterprise 用户推出;GPT-5.5 Pro 向 ChatGPT 中的 Pro、Business 和 Enterprise 用户推出。API 部署需要不同的安全保障措施,我们正与合作伙伴和客户紧密合作,制定大规模服务的安全要求。我们将很快把 GPT-5.5 和 GPT-5.5 Pro 带到 API。
OpenAI 正在构建智能体 AI 的全球基础设施,让世界各地的个人和企业都能借助 AI 完成工作。过去一年,我们见证了 AI 如何显著加速软件工程。随着 GPT-5.5 在 Codex 和 ChatGPT 中的应用,同样的变革正开始延伸到科学研究以及人们在计算机上进行的更广泛的工作中。
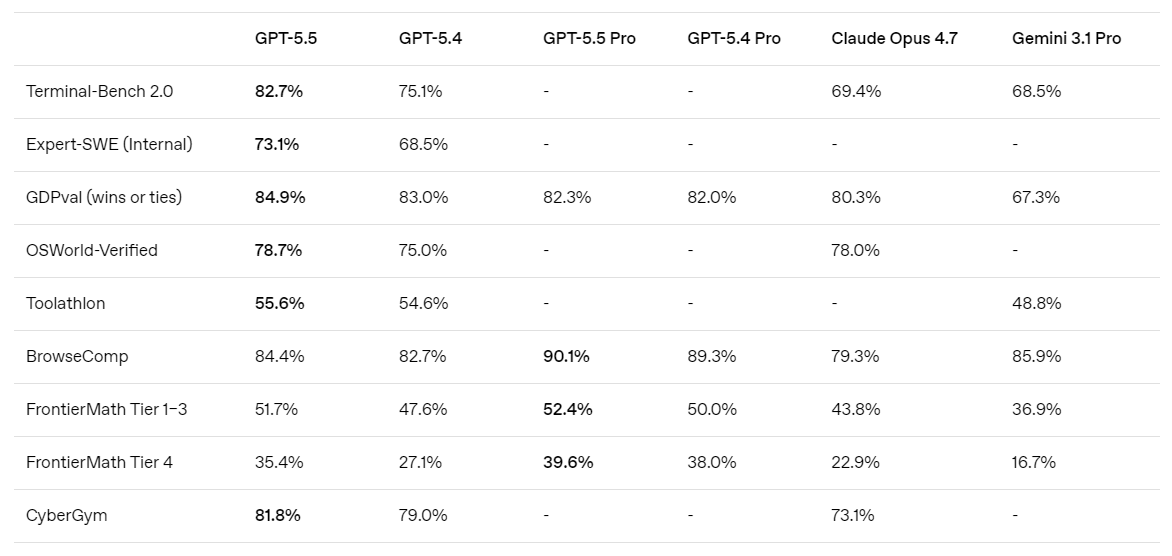
在这些领域,GPT-5.5 不仅更智能;它在解决问题的方式上也更高效,通常能用更少的 token 和更少的重试次数达到更高质量的输出。在 Artificial Analysis 的编程指数上,GPT-5.5 以竞争前沿编程模型一半的成本实现了最先进的智能水平。
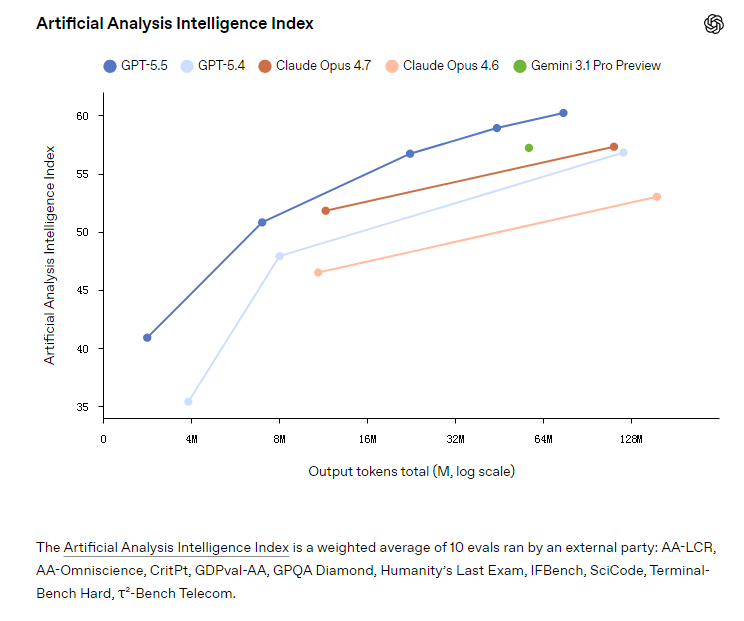
GPT-5.5 是我们迄今为止最强的智能体编程模型。在 Terminal-Bench 2.0(测试需要规划、迭代和工具协调的复杂命令行工作流)上,它达到了最先进的 82.7% 准确率。在 SWE-Bench Pro(评估真实 GitHub 问题解决能力)上,它达到了 58.6%,一次性端到端解决的任务数量超过以往模型。在 Expert-SWE(我们针对长周期编程任务的内部前沿评估,中位估计人类完成时间为 20 小时)上,GPT-5.5 同样超越了 GPT-5.4。
在这三项评估中,GPT-5.5 在提升 GPT-5.4 得分的同时,使用了更少的 token。
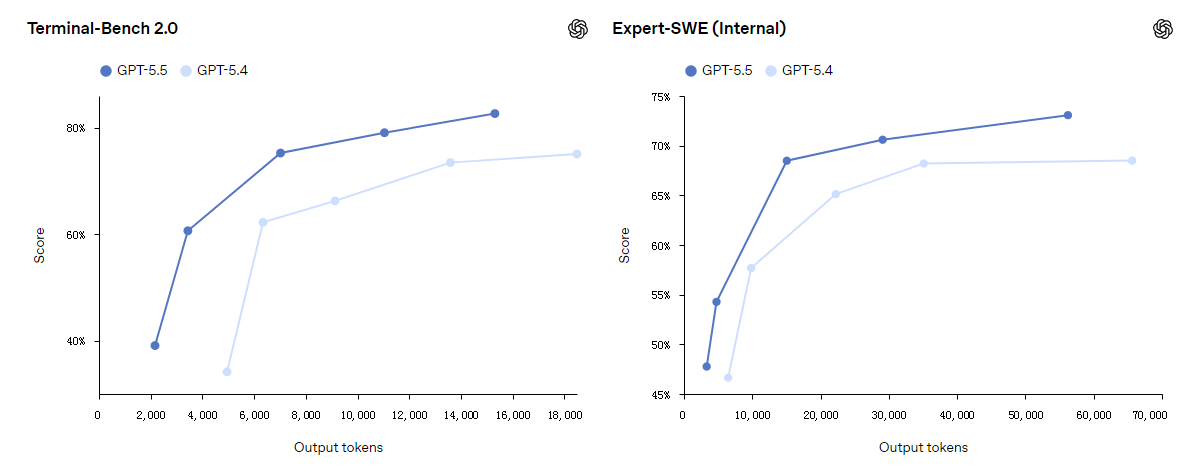
该模型的编程优势在 Codex 中表现得尤为明显,它可以承担从实现和重构到调试、测试和验证的各类工程工作。早期测试表明,GPT-5.5 在真实工程工作所依赖的行为上表现更好,例如在大型系统中保持上下文、推理模糊故障、用工具验证假设,以及将变更贯彻到周围代码库中。
除了基准测试之外,早期测试者表示 GPT-5.5 展现出更强的系统形态理解能力:理解某处失败的原因、修复需要落在哪里,以及代码库中哪些其他部分会受到影响。
