今天我们来继续学习python的函数,学习参数传递的一些基本规则。
我们在学习数据类型的时候,知道python的数据类型有两类,不可修改型(数字、字符串等)和可修改型(列表、字典等)(不记得的童鞋可以点击链接回忆一下)。可修改型和不可修改型作为函数参数时有较大的区别。我们下面通过几个简单的例子来说明。
输出结果:
id of b: 9086048
value of b (before): 99
id of a(initially): 9086048
id of a(assign): 9085696 #创建了新对象
value of a: 88
value of b (after): 99 #函数外部的b不变
从输出结果我们可以清楚看到,刚进入函数时,a指向了b,也就是说b的对象传递到了函数内部。当把a赋值成88时,a指向了一个新创建的对象,对象的值是88。当函数func执行结束后,b的值没有受到影响,仍是99。
是乎有点绕,我们来提取核心内容:
传递的是对象b,而非数值99。
由于b是不可修改的数据类型,对函数的参数a赋值时,在函数内新创建一个对象,然后用a指向这个对象。
这个新对象是函数内部变量,作用域仅在函数内部,对外部的全局变量没有影响。
那对于可修改类型的列表和字典有什么不一样的呢?我们通过下面的例子来看。
输出结果:
id of b: 140298248703240
value of b (before): [1, 2, 3]
id of a(initially): 140298248703240
id of a(assign): 140298248703240 #没有创建新对象
value of a: [4, 2, 3]
value of b (after): [4, 2, 3] #外部的值被修改
示例二的输出结果表明函数内部并没有创建新的列表。当修改列表元素时,实际上修改的就是函数外部的列表。函数执行结束后,看到外部的列表确实被修改。
使用可修改型参数给我们提供了修改全局变量的方法。但如果使用不当,可能会误修改。我们要牢记这一点。那么有没有好的方法来避免这种风险呢?有!
一般有两种方法:
使用元组(Tuple)代替列表。
函数一开头把列表拷贝到本地。
输出结果:
TypeError: 'tuple' object does not support item assignment
示例三表明,把列表强制转换成元组再传递给函数,当函数内部有修改数组的操作时就会报错,提示元组不能赋值。这种方法虽简单暴力,但有局限性。局限性是列表数据类型提供的方法,如append、remove等,都不能使用。
再看下面的示例四,示例中提供了一种更优雅的解决方案。
输出结果:
id of b: 140122896936264
value of b (before): [1, 2, 3]
id of a(initially): 140122896936264
id of a(assign): 140122896936328 #创建了新对象
value of a: [4, 2, 3]
id of b: 140122896936264
value of b (after): [1, 2, 3] #外部列表没有被修改
在函数一开头,通过a = a[:]创建了一个新的列表对象,a指向了这个新对象。那么函数内部接下来的所有操作都只针对这个新的列表对象。
我们知道verilog有两种实例化方式,按位置顺序和按端口名称。同样python也有这两种方式。例如下面的两个例子。
示例六里,按名称调用时,变量的先后顺序就不重要了。按名称调用的好处是一目了然。
另外,函数定义时还可以指定参数默认值。如下面的例子:
这个例子里,对于定义了默认值的参数,在调用时如果不需要修改就可以省略。这样可以让代码更简洁。
注意,函数定义时,没有默认值的在前,有默认值的在后。像def func(a, b=2, c)是不符合python语法的,会报错。
按位置顺序和按名称调用可以混用。如下面的示例:
注意,混合调用时要讲究顺序,先按位置、后按名称调用。否则语法会报错。
我们都知道print()函数支持任意多个参数,倒底是怎么实现的?其实python的参数还有两种*和**。*表示把传递的参数看作一个元组,**表示把传递的参数看作是一个字典。例如:
在示例九里,如果我们在函数内部做元组的解析和打印,是不是就可以实现自己的print()函数了呢?(习题2)
由于*、**不确定参数的个数,所以一般放在参数列表的最后,表示剩下来的其它参数。
如果*不在最后,函数调用时*后面的参数需要按名称调用。不然没办法判断*的参数到哪里结束。如下面的例子:
一般比较好习惯是,参数按位置 -> 名称 -> * -> ** 顺序定义及调用。
函数的参数传递细节问题非常多,我们写代码时要多用简单、容易理解的编码风格。对于参数我们总结如下几点:
注意可修改型(如数字、字符串)和不可修改型(如列表、字典)参数的区别,并学会利用拷贝避免风险。
按位置和按名称两种调用方式,复杂的情况下多用按名称调用。
学会用*和**实现参数个数不确定的函数。
注意参数定义和调用时按位置、名称、*、**的顺序。
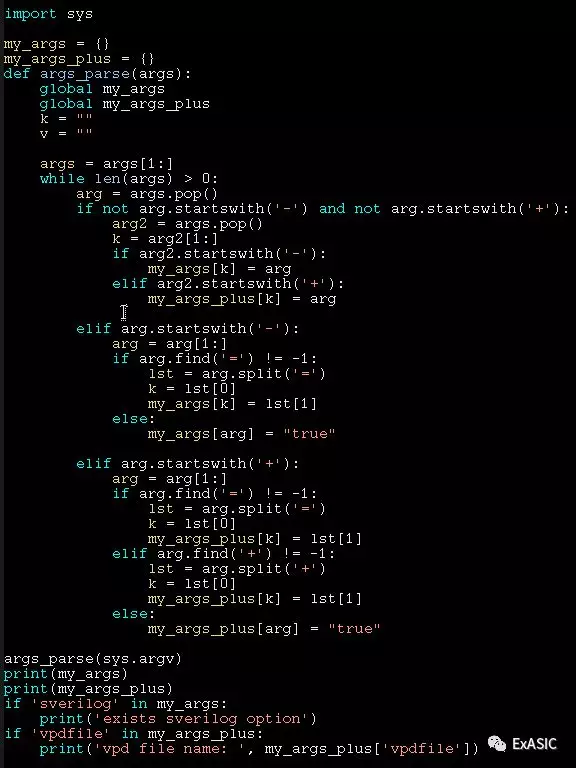
实现一个函数args_parse(),解析命令行的参数,把结果存在一个字典变量中。
实现自己的print_anything(),支持任意个任意类型的参数。
我们假设有类似vcs的参数:-R -full64 -sverilog -timescale=1ns/1ps -y rtl -f rtl.flist +warn=none +vpdfile+debug.vpd
结果输出:
$ python3 func_args_ans1.py -R -full64 -sverilog -timescale=1ns/1ps -y rtl -f rtl.flist +warn=none +vpdfile+debug.vpd
{'f': 'rtl.flist', 'y': 'rtl', 'timescale': '1ns/1ps', 'sverilog': 'true', 'full64': 'true', 'R': 'true'}
{'vpdfile': 'debug.vpd', 'warn': 'none'}
exists sverilog option
vpd file name: debug.vpd
点评:主要的思路就是逆序判断参数前有无-或+。把解析后参数存在字典很方便后续脚本的识别和判断。
利用*参数类型,有函数内部拷贝列表到内部变量,再逐个打印。

结果输出:
$ python3 func_args_ans2.py
1
abc
[4, 5, 6]
{'name': 'dut', 'area': '40um2'}
分享数字集成电路设计中的经验和方法。分享让工作更轻松。

