f = open('mytest.v', 'w')
# rtl = ...
f.write(rtl)说明:这种方法相当简单朴素,python做出需要的字符串,写到文件。好处是不需要技巧,坏处是python代码可维护性较差。
与第一种的差异是,把各种可配置的信息存到配置文件里,如excel、json、yaml,在脚本里读取配置文件再用第一种方法生成字符串。
这种方法的好处是脚本相对固定,只需要修改配置文件就可以重新生成verilog代码。但python脚本还是相对较乱,因为从配置参数到目标verilog中间需要各种字符串处理,如正则替换,format,进制转换等。当目标verilog的格式要求一变,python脚本还是需要重写。
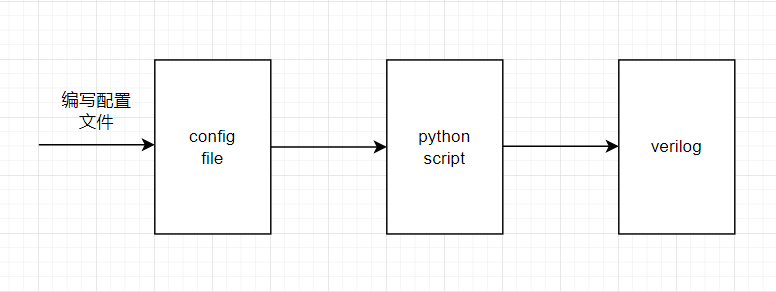
现在我们来利用模板语言,比如jinja2,https://docs.jinkan.org/docs/jinja2/ ,把配置参数与目标verilog格式拆分开来。
如下图,有两个模板,RTL模板和验证模板,用同一个配置参数经过不同的模板,就可以得到不同的代码。配置参数与模板转换的过程是由模板引擎来实现,不需要我们再重新造轮子。
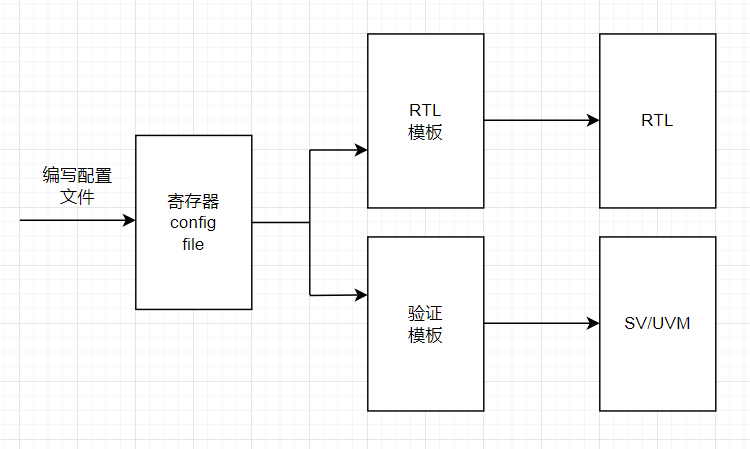
这种方法的好处是只需要把精力花了编写模板身上,而其它部分都是由现成的库来实现,这样就只需要写很少量的python代码了。缺点是这种模板语言与Verilog语言本身有比较大的差异,需要稍微学习一下。
在Verilog代码注释里嵌入几行python代码,而保持大部分Verilog不动。比如下面的例子:
always@(posedge clk, negedge rst_n)
if(!rst_n)
q[7:0] <= 8'b0;
else begin
// PYTHON_BEGIN
// import random
// data = []
// for i in range(8)
// data.append(random.randint(0, 1))
// for i in range(8):
// print('q[{}]'.format(data[i]))
// PYTHON_END
end可见,这串代码的注释中用PYTHON_BEGIN和PYTHON_END括起了一段python代码。我们需要提取出这段python,把python的执行结果替换到原处。
当然为了保证代码可以再次生成,我们不能删除python源码,而是需要在注释下方生成。重新生成时会先删除PY_VLG_BEGIN和PY_VLG_END之间的verilog代码。
always@(posedge clk, negedge rst_n)
if(!rst_n)
q[7:0] <= 8'b0;
else begin
// PYTHON_BEGIN
// import random
// data = []
// for i in range(8)
// data.append(random.randint(0, 1))
// for i in range(8):
// print('q[{}] <= {};'.format(i, data[i]))
// PYTHON_END
// PY_VLG_BEGIN
q[0] <= 0;
q[1] <= 1;
q[2] <= 0;
q[3] <= 0;
q[4] <= 1;
q[5] <= 1;
q[6] <= 1;
q[7] <= 0;
// PY_VLG_END
end这个“提取->执行->替换”的脚本具有通用性,编写起来比较简单。不需要频繁修改。
当verilog里内嵌的python功能接近,或者有共性时,就可以把这种处理函数写到一个py库里,用时import进来。
优势:只需要维护一份verilog文件(不需要额外的python脚本了),对设计工程师友好。缺点:每个公司都需要建立自己的共用py库,当库越来越庞大时,新人或者换工作后就需要重新学习或者重新零开始。
每个人单独搞一套就会变得不可持续。可以以开源项目的方式,爱好者共同开发和维护,不断迭代,形成行业规范。例如:HDLGen( https://github.com/WilsonChen003/HDLGen )。
但很可能贡献者有限,停止维护,慢慢荒废。
比如SpinalHDL( https://thucgra.github.io/SpinalHDL_Chinese_Doc/ )、Chisel( https://www.chisel-lang.org )这种基于Scala的硬件开发工具。优点:有规范,行业标准。缺点:创新得太彻底,学习成本非常高,遇到问题很难找到地方咨询。并与现有的Verilog开发流程差异较大,DSL自成一套设计和验证的方法。
分享数字集成电路设计中的经验和方法。分享让工作更轻松。

